In my first post I made reference to the idea of microservice isolation a number of times. I figured that this is as good of a topic as any to start with. The concept of isolation and boundaries is core to how you build your microservices. Let’s leave boundaries for another post because it’s a complicated and deep concept by itself.
It doesn’t matter who you listen to or read, microservice isolation is going to be in the content. Why are they consistently bringing it up? Isolation is at the heart of microservices. A microservice is meant to be architected, created, deployed, maintained and retired without affecting any other microservice. You can’t do any, let alone all, of that without good isolation.
Databases
Probably the most common point made when talking about isolation is database sharing, or better stated, the idea that you should avoid it. Traditional monolithic application development usually sees that one large codebase working with one large database. Any area of the monolith can access any area of the database. Not only does the monolith’s codebase usually end up looking like a plate of spaghetti, so does the monolithic database. I can’t tell you the number of times that I’ve worked on brownfield codebases that have issues with data access, deadlocks being the most common. No matter how well factored a monolithic codebase is, the fact remains that the single database is an integration point for all the different moving pieces in that codebase.
To be able to release a microservice without affecting any other microservice we need to eliminate any integration that occurs at the database level. If you isolate the database so that only one microservice has access to it you’ve just said that the only thing that will be affected if the database changes is that one microservice. The testing surface area just shrunk for any of those changes. Another benefit is that have fewer pieces of code interacting with the database so you can, in theory, better control how and when that code does its thing. This makes it easier to write code that avoids deadlocks, row locks, and other performance killing or error inducing situations.
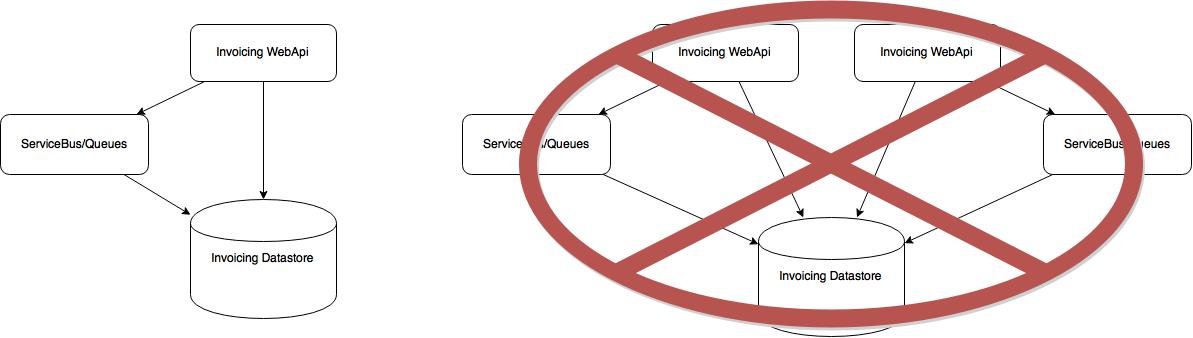
If you listen to enough people talk about microservices for a long enough time you’ll hear a common theme; 1 database per microservice. I’m going to disagree with the masses here and tell you something slightly different. You should have a minimum of 1 data store for each of your microservices. The difference is subtle but it’s important in my mind. There are times when you might want to store data in multiple different ways within one microservice. As an example you may be writing a Marketing Campaign microservice. A RDBMS or noSQL database makes a lot of sense for storing the information about campaigns, content, targets, etc. But if you need to do statistical analysis of the campaign feedback (i.e. email bounces, unsubscribes, click-throughs, etc.) RDBMS and noSQL might not make the most sense. You might be better served with a data cube or some other type of data storage.
Is it going to be normal to have multiple data stores for one microservice? No…but you shouldn’t be worried if it does happen as long as you stay true to one thing: the microservice owns the data stores and no other microservices can access them.
Deployment Isolation
One of the primary goals of moving to a microservices architecture is that you’re able to deploy changes to one microservice without affecting any others. Additionally you want to ensure that if a microservice starts to fail it’s not going to bring down the other microservices around it. As such, this means that you’re going to need to have each microservice deployed in complete isolation. If you’re on a .NET stack you can’t share AppPools between them. If they do changes to the permissions or availability of that AppPool could (or likely will) affect other microservices. My experience with Apache is quite limited, but I’m sure there are similar concerns there.
One of the big current talking points around microservices is Docker. Building compartmentalized and deployable contiguous packages seems to address this goal. The only current issue is that Docker builds a smaller fence around the technologies that you can choose when solving your problems. Docker, currently, doesn’t support Windows based applications. You can build your .NET apps and run them in a Linux Docker container, but that’s as close as you get…which might not be close enough for some “E”nterprise-y places.
Another piece of the deployment puzzle is what is commonly referred to as ‘lock-step’ deployments. A lock-step deployment is one where deploying one microservice requires a mandatory deployment of a different one. Usually this happens because the two components (or microservices in this case) are tightly coupled. Usually that coupling is related to api signature changes. I’m going to do a whole blog post on this later in the series, but its suffice to say for now that if you are doing lock-step deployments you need to stop and solve that problem before anything else. If you aren’t doing lock-step deployments you need to be vigilant to the signs of them and fight them off as they pop up.
Something that makes noticing lock-step deployments more difficult to notice, but is going to be mandatory in your deployment situation, is automation. Everything about your deployment process will need to be automated. If you’re coming from a mentality, or reality, of deploying single, monolithic applications you’re in for a big shock. You’re no longer deploying one application. You’re deploying many different microservices. There are a lot more deployable parts, and they’re all individually deployable. My project only had 4 microservices and we found that manual deployment was worse than onerous. Everything from the installation of the microservice to the provisioning of the environments that the microservice will run in has to be automated. Ideally you’re going to have automated verification tests as part of your deployment. The automation process gives you the ability to easily create frictionless lock-step deployments though…so you’re going to have to be vigilant with your automation.
I know that some of you are probably think “That’s all fine and good but I will always have to change APIs at some point which means that I need to deploy both the API and the consumers of the API together”. Well, you don’t have to…which kind of leads to…
Microservice <-> Microservice communication
At times there will be no way to avoid communication between two microservices. Sometimes this need to communicate is a sign that you have your bounded context wrong (I’ll be going over bounded contexts in a future post). Sometimes the communication is warranted. Let’s assume that the bounded contexts are correct for this discussion.
To keep microservices isolated we need to pay attention to how they communicate with each other. I’m going to do an entire blog post on this but because there can be so many things that come into play. It’s safe to say that you need to pay attention to a couple of different key pieces. First, take the approach of having very strict standards for communication between microservices, and loose standards for the technology implementations within each microservice. If you’re going to use REST and JSON (which seems to be the winning standard) for communication. Be strict about how those endpoints are created and exist. Also, don’t be afraid to use messaging and pub/sub patterns to notify subscribing microservices about events that happen in publishing microservices.
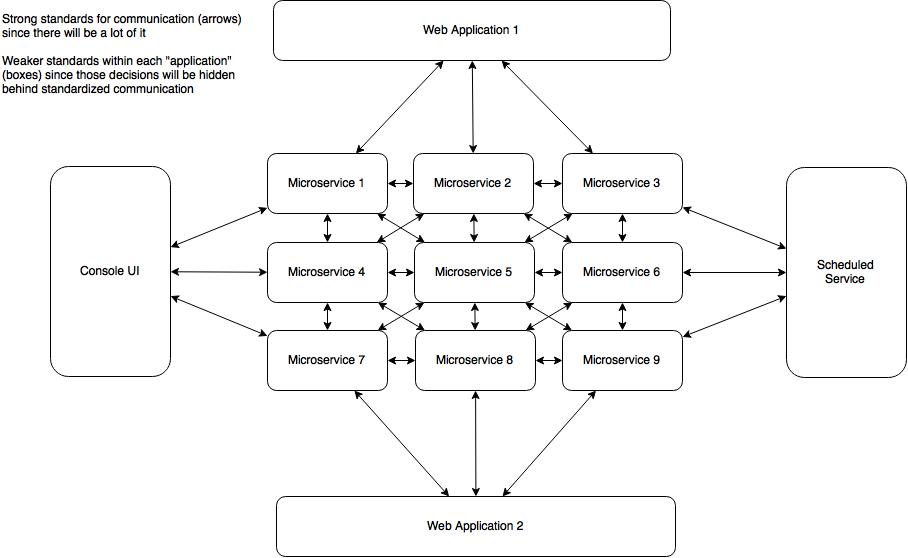
The second thing that you need to do, which is related to the first, is spend some time up front in deciding what your API versioning story is going to be. API versioning is going to play a big part in maintaining deployment isolation. Your solution will probably require more than simply ‘adding a version header’ to the communication. You’re probably going to need infrastructure to route communications to different deployed versions of the APIs. Remember that each microservice is an isolated deployable so there is no reason that you couldn’t have two or more instances (say v1 and v2) up and running at any one time. Consuming microservices can continue to make uninterrupted use of the v1 endpoints and as they have time/need they can migrate to v2.
Source code
Now that we’ve talked about the architecture of your microservices let’s take a look at the source code. So far we’ve been talking about isolating the microservice data stores, the deployment strategy and cross microservice communication. In all of those areas we didn’t come straight out and say it but each microservice is a separate application. How do you currently organize separate applications in your source control tool? Probably as separate repositories. Keep doing this. Every microservice gets its own repository. Full Stop. The result is that you’re going to see an increase in the number of repositories that you have to manage. Instead of one (as you’d probably have with a monolith) repository you’re going to have 1+N where N is the growing number of microservices that you’re going to have.
How you organize the pieces of the puzzle within that application is going to depend on many things. It’s going to depend on the components the microservice needs. The more “things” (service buses, web services, background processing, etc) then the more complicated the application’s source code structure is likely to be. You might have four or five assemblies, a couple or executables and other deliverables in a single microservice. As long as you have the minimum required to deliver the required functionality then I think you’ll be okay. More moving pieces can mean that you’re doing too much in the microservice though. It could be creeping towards monolith territory. So carefully watch how each microservice evolves into it’s final deliverable.
Another thing to consider is how you perform development isolation in your VCS. I’m not going to get into a branches vs feature-toggles discussion here, but you have to do something like that in your development practices. Things are going to move a lot faster when you’re developing, enhancing and maintaining microservices. Being able to rapidly turn around bug fixes, feature additions or changes becomes a competitive advantage. You need to work within your VCS in a manner that supports this advantage.
Continuous Integration
Following in the steps of the source code is the continuous integration process. Because every microservices is an independent application you’re going to need to have CI processes to support each and every microservice. This was one of the things that caught my project off guard. We didn’t see it coming but we sure noticed it when it happened. As we created new microservices we needed to create all of the supporting CI infrastructure too. In our case we needed to create a build project for every deployment environment that we had to support. We didn’t have this automated and we felt the pain. TeamCity helped us a lot but it still took time to setup everything. This was the first hint to us that we needed to automate everything.
Teams
There is a lot of talk about sizing microservices (which, again, I’ll cover in a future post). One of the things that continually seems to come up in that discussion is the size of teams. What is often lost is that teams developing microservices should be both independent and isolated…just like the applications that they’re building. Conway’s law usually makes this a difficult prospect in a ‘E’nterprise development environment. The change to developing isolated and compartmentalized microservices is going to require team reorganization to better align the teams and the products being produced.
Teams need to be fully responsible for the entirety of the microservice that they’re developing. They can’t rely on “the database guys to make those changes” or “infrastructure to create that VM for us”. All of those capabilities have to be enabled for and entrusted to the team doing the development. Of course these independent teams will need to communicate with each other, especially if there one of the teams is consuming the other’s microservice. I think I’ll have a future post talking about Consumer Driven Contracts and how that enhances the communication between the teams.
Summary
When talking about isolation and microservices many conversations tend to stop at the “one microservice, one database” level. There are so many other isolation concerns that will appear during the process of building, deploying and maintaining those microservices. The more I’ve researched and worked on microservices the more I’ve become of the opinion that there are a bunch of things related to microservices that we used to get away not doing on monolithic projects but that we absolutely can’t ignore anymore. You can’t put off figuring out an API versioning scheme. You’re going to need it sooner than you think. You can’t “figure out your branching strategy when the time comes” because you’re going to be working on v2 much sooner than you think.
Isolation is going to save you a lot of headaches. In the case microservices I’d probably consider leaning towards what feels like ‘too much’ isolation when making decisions rather than taking what likely will be the easier way out of the problem at hand.